
算法复杂度
算法复杂度分为时间复杂度和空间复杂度。
时间复杂度是度量算法执行的时间长短,简单的理解就是执行语句的条数。如果有循环和递归,则忽略简单语句,直接算循环和递归的语句的执行次数。
空间复杂度:行完一个程序所需内存的大小。
常用时间复杂度所耗时间排序:
O(1)<O(logn)<O(n)<O(nlogn)<O(n^2)<O((n^3)<O(2^n)<O(n!)<O(n^n)
排序算法
冒泡排序:
|
|
冒泡排序是我们学C语言的第一个接触的排序算法,也是一种简单的算法,它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,最佳时间复杂度正序O(n),最差时间复杂度反序O(n^2),平均时间复杂度O(n^2),空间复杂度O(1),不占用额外内存,稳定,数据量小一般都用这个,但也不尽然,看具体情况。
动图展示啦啦
选择排序:
选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
|
|
最佳最坏平均情况都是都为0(n^2),而空间复杂度同冒泡一样都为O(1),但与冒泡不同的是,选择排序虽然表现最稳定,但因为无论什么数据进去都是O(n^2)的时间复杂度,所以,在算法层面并不稳定,适用于越小越好的数据规模。
动图展示啦啦
插入排序
插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间
|
|
这个适用于排序小列表,最佳与最坏情况都为O(nlog2 n),平均情况为O(nlogn),空间复杂度同上,该排序改进了插入排序,减少了比较的次数。是不稳定的排序,因为排序过程中元素可能会前后跳跃。
找不到动图,泪奔
归并排序
归并排序是另一种不同的排序方法,因为归并排序使用了递归分治的思想,所以理解起来比较容易。其基本思想是,先递归划分子问题,然后合并结果。把待排序列看成由两个有序的子序列,然后合并两个子序列,然后把子序列看成由两个有序序列。。。。。倒着来看,其实就是先两两合并,然后四四合并。。。最终形成有序序列。
|
|
基于分治法的归并排序适用于排序大列表,代价是需要额外的内存空间。空间复杂度为O(n),时间复杂度为O(nlogn)。比较稳定,在大列表排序情况下建议使用。
动图展示啦啦
总结
这里先写5种排序方式,感谢在我学习之路上的各位大佬。
秦至
不知道名字哎
作为一个本学期暂时没学习过数据结构和离散数学的小rookiy,我去找别人借了本大话数据看了下,发现还是直接记结论吧,因此后面的几种暂时搁置下,对这几个先熟络一下,另外展示下所有排序图片的总结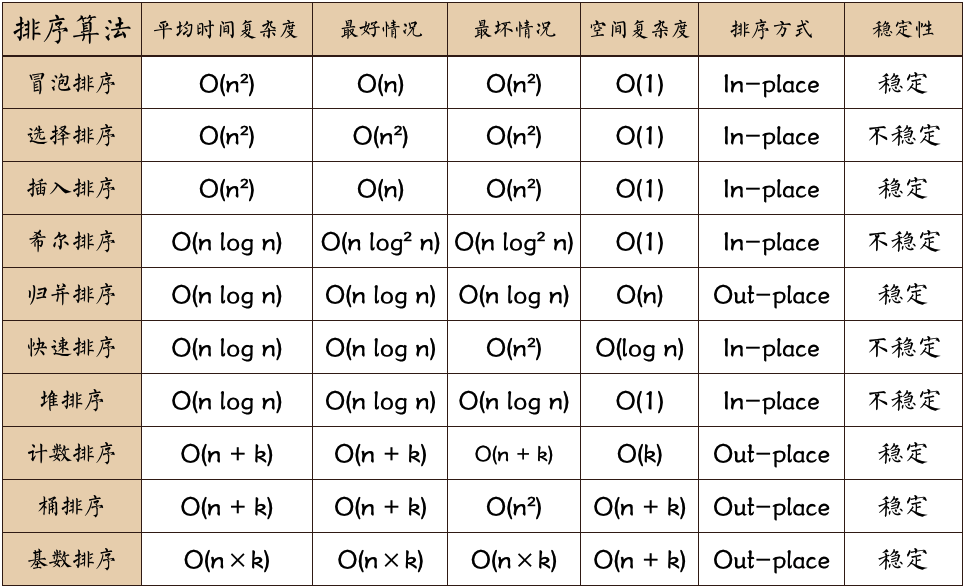
推荐
这里有个好玩的东西可以推荐一下
visualgo
那些数据结构可在这可视化,虽然都是英文,但也有中文的,不用担太多心,科科。